Zusammenfassung der Ergebnisse
Artificially Correct Hackathon 2021

Zwischen dem 1. und 3. Oktober kamen Übersetzer*innen, Aktivist*innen und Softwareentwickler*innen aus der ganzen Welt zusammen, um am Artificially Correct Hackathon des Goethe-Instituts teilzunehmen. 12 Teams hatten 52 Stunden Zeit (in denen sie viel Kaffee brauchten), um eine Mission zu erfüllen: innovative, zukunftsweisende Ideen und Projekte zu entwickeln, die helfen, Bias in Sprache und maschineller Übersetzung zu bekämpfen.
Von Alana Cullen und Priyanka Dasgupta
Die Notwendigkeit des Hackathons
Jedes Wort ist mit einer bestimmten Geschichte, einer bestimmten Bedeutung und einem bestimmten Kontext verbunden. Als diejenigen, die Sprache benutzen, können wir unsere Worte bewusst wählen. So dient uns Sprache nicht nur zur Kommunikation, sondern als Mittel für Veränderung. Warum entscheiden wir uns nicht, an Stelle des englischen Begriffs ‚chairman‘ (Vorsitzender) die neutraleren Formen ‚chairperson‘ oder ‚chair‘ (Vorsitzende) zu verwenden? Warum verbinden wir die eigentlich neutrale englischsprachige Berufsbezeichnung ‚nurse‘ sofort mit der explizit weiblichen deutschen Übersetzung ‚Krankenschwester‘ und nicht mit ‚Pflegeperson‘, was alle Gender einschließen würde? Stereotype sind nicht nur in unseren Köpfen verankert, sondern auch in der Sprache, die wir benutzen.„Sie ist hübsch“
„Er ist schlau“
„Er liest“
„Sie spült das Geschirr“
Es gibt diesen Bias in Künstlicher Intelligenz (KI) für maschinelle Übersetzungen, weil sie mit Datensätzen trainiert wird, die menschlichen Bias enthalten. Auf diese Weise lernt KI die Standardmuster unserer Sprache.
Nicht nur Gender-Bias ist in KI eingebaut worden, sie reproduziert auch rassistische Vorurteile. Beispielsweise wird aufgrund von zeitgenössischer Kinderliteratur aktuell der englische Begriff ‚half blood‘ (Halbblut) stark verbreitet und damit als Teil des gängigen Sprachgebrauchs etabliert, obwohl er historisch gesehen als rassistische Beleidigung diente. Somit wird sprachlicher Bias fortgeführt, denn KI lernt von ihren Entwickler*innen – je mehr Vorurteile das System sieht, desto vorbelasteter wird sein Standardverhalten.
Diese Erkenntnis kann uns den nötigen Anstoß geben, damit wir uns auf den Weg in Richtung neutralerer, weniger vorurteilsbelasteter Übersetzungen machen. Natürlich ist echte Neutralität in einer Welt mit so vielen Machtungleichheiten nicht gänzlich erreichbar, aber wir können trotzdem darauf hinarbeiten, dass KI für mehr Menschen besser funktioniert. Die vielversprechenden Lösungsansätze, um dieses Ungleichgewicht zu vermindern, zeigen das Potenzial, das der digitale Wandel mit sich bringt – und zwar für alle.
Lösungen entwickeln
Die Teilnehmenden des Hackathons fokussierten sich genau darauf: innovative Lösungen zu finden. Es gab fünf Challenges oder Aspekte von Bias in KI, in die die Teams ‚hacken‘ konnten. Dazu gehörte die Entwicklung von Nachbearbeitungsprogrammen, die zu mehr Gendergerechtigkeit in maschineller Übersetzung beitragen, sowie die Suche nach Methoden zur Identifizierung von Sätzen, die bei maschineller Übersetzung besonders anfällig für Bias sind.
Neben dem Hacken selbst wurde den Teilnehmenden die Möglichkeit geboten, Keynote Vorträgen von Expert*innen aus den Bereichen KI, Gender oder Critical Race Studies beizuwohnen - Ylva Habel, Dagmar Gromann und Manuel Lardelli, Danielle Saunders und Sheila Beladinejad teilten ihr Wissen und ihre Ideen:
Was den Umgang mit Bias in Übersetzungen so schwierig macht, sind Sprachveränderungen. Unsere Vorstellungen von Gender, gegenderter Sprache und Stereotypen verändert sich mit der Zeit.
Danielle Saunders, Hackathon Keynote-Speaker*in
Die Hackenden hatten während des Wochenendes immer wieder die Gelegenheit mit KI-Expert*innen zu sprechen, die sie bei der Entwicklung von Lösungen unterstützten.
Alle 12 Teams leisteten fantastische Arbeit bei der Entwicklung innovativer Lösungen, um den Bias in KI zu reduzieren. Am letzten Tag des Hackathons wählte die Jury fünf Teams aus, die ihre Ideen ausführlicher vorstellen sollten.
Es hat mir viel Spaß gemacht, am Hackathon teilzunehmen und meine eigene Expertise in kreative Lösungsansätze für die Reduktion von Bias in maschineller Übersetzung einfließen zu lassen. Es war eine großartige Möglichkeit, mit Menschen aus verschiedenen Bereichen zusammenzuarbeiten und unsere Ideen zu kombinieren.
Dr. Antje Bothin, Hackathon-Teilnehmerin
Der Hackathon brachte viele interessante Ideen zum Vorschein, die in den intensiven Hack-Sessions entstanden sind. Teams entwickelten Algorithmen, um den „Abstand“ zwischen vorurteilbehafteten Wörtern oder Begriffen, die häufig falsch gegendert werden, zu messen. Ein Team präsentierte einen einfachen Gender-Schalter, der es in der Nachbearbeitung eines Textes erlaubt, zwischen verschiedenen Formen des Genderns hin und her zu springen. Einige Teams betonten die Wichtigkeit inklusiverer Datensätze, um KI zu trainieren, während andere zu diesem Zweck eine Art „Bias-Bibliothek“ entwickelten. Ein weiteres Team entwickelte ein Tool, mit dem Nutzer*innen nicht nur auf Bias in Bezug auf Gender hingewiesen werden, sondern auch auf rassistische Begriffe.
Aus diesen Kurzvorstellungen wurden zwei Gewinner*innenteams ausgewählt, die ihre Lösungsansätze nach dem Hackathon weiter entwickeln werden.
So geht’s weiter
Das Problem mit Bias in KI ist viel zu groß, als das unsere Teams es an einem Wochenende hätten vollständig lösen können, aber irgendwo müssen wir schließlich anfangen. Dass in so kurzer Zeit so vielfältige kreative Lösungsansätze entstanden sind, verdeutlicht aber, dass es reelle Möglichkeiten gibt, die Veränderungen zu erreichen, die wir uns wünschen – mit den richtigen Mitteln und mehr Zeit. Mit ihrem Ziel, KI inklusiver zu machen, trägt die Arbeit aller Hackathon Teams dazu bei, dass vielfältigere Stimmen in KI integriert werden.
Die Gewinner*innen des Hackathons werden ihre Lösungsansätze dank des Preisgeldes von 2500 Euro und der Unterstützung durch Mentor*innen und Ressourcen des Goethe-Instituts weiterentwickeln können.
Wir haben noch einen weiten Weg vor uns, aber jeder Schritt zählt: Die Lösungsansätze, die während des Hackathons entstanden sind, weitere Diskussionen und Bemühungen werden dazu beitragen, die Art und Weise zu verändern, welche Worte wir Menschen wählen und welche in KI verwendet wird; irgendwann wird Sprache inklusiv sein.
Hier gibt es Einblicke in die Projektideen der fünf Teams, die von der Jury zu den Finalist*innen des Artificially Correct Hackathons gewählt worden sind. Alle verfolgen unterschiedliche Ansätze um Bias in KI zu reduzieren:
-
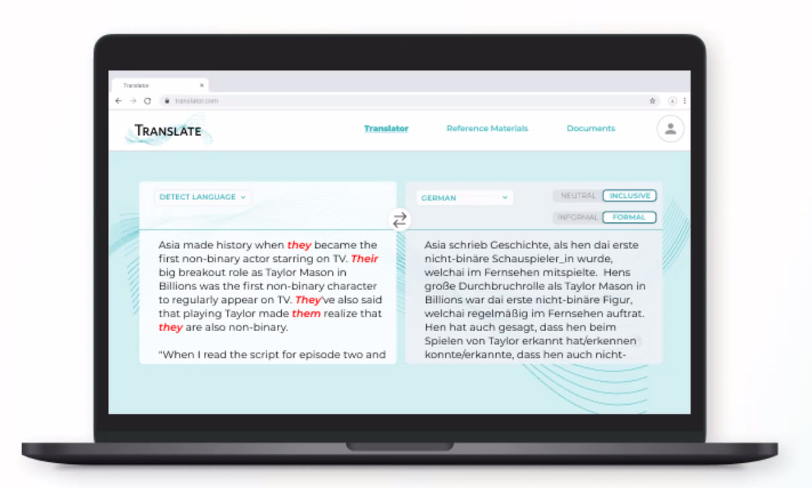
1. Ein Gender-Schalter
Team 2B entwickelte einen Lösungsansatz für die Nachbearbeitung maschinell übersetzter Texte. Ihre Idee ist ein „Gender-Schalter“, der es Nutzer*innen ermöglicht, zu entscheiden, welche Pronomen in der Übersetzung am besten passen. Übersetzer*innen arbeiten mit verschiedensten Textsorten - von literarischen Texten bis hin zu tagesaktuellen Nachrichten – und die Wahl, die der Gender-Schalter ermöglicht, bedeutet, dass die Ergebnisse der maschinellen Übersetzung mit den jeweiligen Anforderungen in Einklang gebracht werden können. Wenn Nutzer*innen die Möglichkeit haben, genderfreie oder genderinklusive Ausdrucksweisen zu wählen, werden sie darin bestärkt, sich für die Sichtbarkeit von geschlechtlicher Vielfalt einzusetzen. -
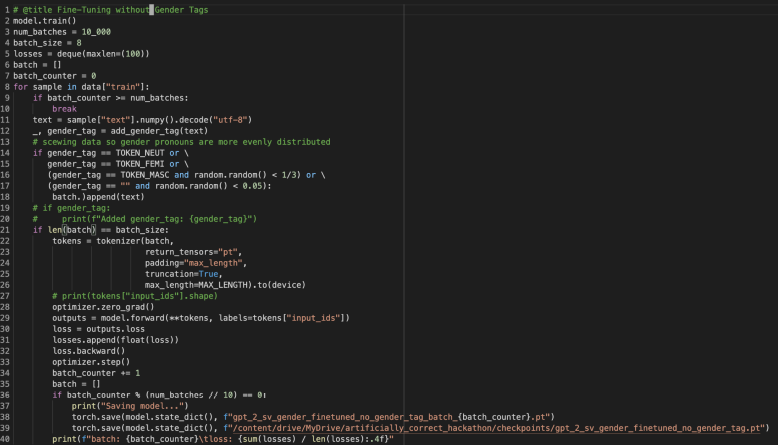
2. Gender Bias messen
Das Team, das sich den Namen Wheatstone Warriors gegeben hat, entwickelte einen Prototypen, um Gender Bias zu messen. Sie nutzten einen Trainingsdatensatz aus Schweden und untersuchten, wie viele männliche, weibliche und geschlechtsneutrale Pronomen auftauchten und kennzeichneten jedes einzelne davon. Die Gender-Markierungen ermöglichten es, die „Abstände“ des Bias zu messen und weitere Beobachtungen anzustellen: Je größer der Abstand, desto anfälliger war der Satz für Bias. Das Modell dient als Grundlage und Feinabstimmungen werden es möglich machen, zu erkennen, in welchen Fällen Bias besonders häufig auftritt. Auf diese Weise konnte das Team zeigen, dass Gender-Bias in Daten keine unüberwindbare Hürde darstellt. Trainierte Maschinen können optimiert werden, um die Reproduktion von Vorurteilen zu vermindern. -
3. Crowdsourcing für vielfältige Datensätze
Als nächstes war das Team 1A an der Reihe, das es sich zur Aufgabe gemacht hat, Datensätze mit mangelnder Vielfalt zu untersuchen. Um die Vielfalt zu erhöhen, schuf das Team eine Plattform, die unterrepräsentierte Gruppen ermutigt, Sprachdaten beizusteuern. Je vielfältiger die Daten, desto besser lernt der Computer, Sprachen aus der ganzen Welt in allen Dialekten zu erkennen – Ziel des Teams: KI für alle zugänglich und repräsentativ zu machen. Der Prototyp lockt Nutzer*innen mit einem Maskottchen an - in diesem Fall mit einem freundlichen Ei. -
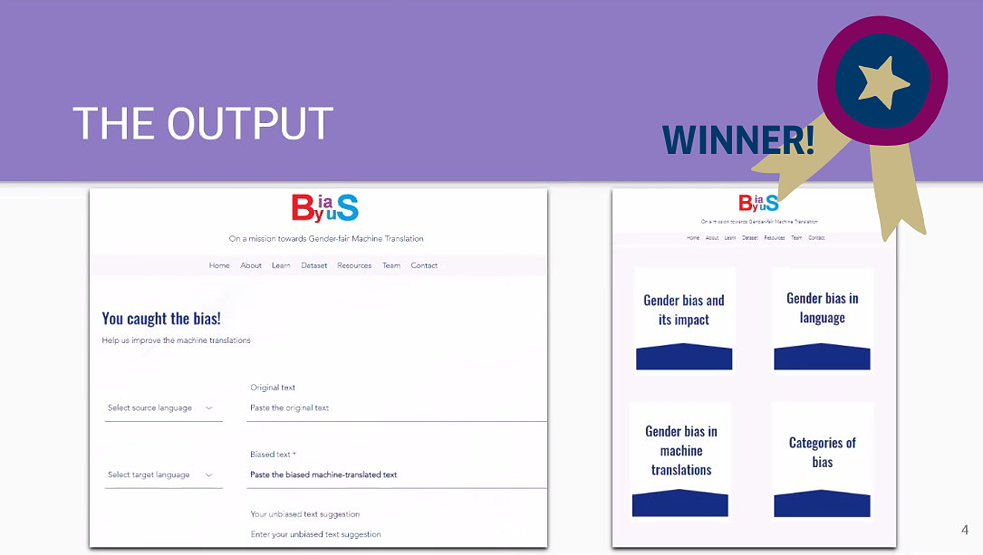
4. Gemeinsam Vorurteile abbauen
Das Team BiasByUs erstellte eine Website, die als „Bibliothek“ für Bias in Übersetzungen dient. Sie sammeln vorurteilsbelastete Übersetzungsbeispiele, die typischerweise in Übersetzungsprogrammen auftreten, mithilfe von Crowdsourcing. Das Zusammentragen dieser Beispiele soll dazu beitragen, dass KI künftig besser trainiert werden kann. Nutzer*innen werden von diesem Team direkt mit einbezogen, um auf Bias aufmerksam zu machen. So wird deutlich, dass wir gemeinsam gegen Vorurteile in der Welt vorgehen können. Die Website ist aber nicht nur eine Sammelstelle für Bias, sondern dient auch dazu, mehr Bewusstsein für die Thematik zu schaffen. -
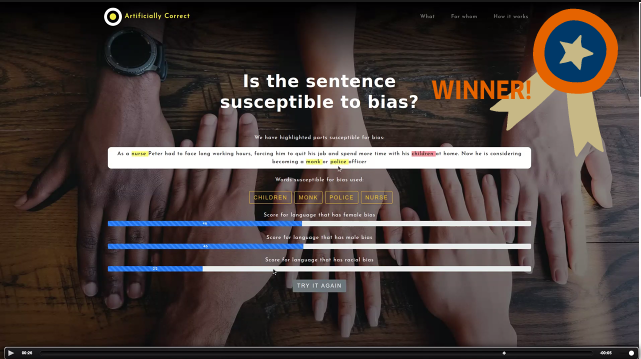
5. Anfälligkeit für Bias identifizieren
Das Team 4c konzentrierte sich auf eine Schwachstelle von Google Translate und anderen Deep-Learning Systemen: die Schwierigkeit komplexe Inhalte zu verstehen. Je höher die Komplexität eines Textes, desto eher werden Wörter auf unpassende Weise oder gar falsch übersetzt. Der Lösungsvorschlag des Teams ist ein Tool, das Bias reduziert, indem es Nutzer*innen anzeigt, wie anfällig ein Satz für Bias in Bezug auf Gender und Race ist. Es identifiziert und analysiert den größeren Kontext des Satzes und hebt folglich Sätze und Phrasen hervor, die anfällig für Bias sind. Dieses Tool könnte Übersetzer*innen zusätzlich bei der Nachbearbeitung von Texten helfen, indem es die Stellen im maschinell übersetzten Text hervorhebt, die ein Mensch noch mal überprüfen sollte.

Hier gibt es Video-Interviews mit den zwei Gewinner*innen-Teams, die von Ihren Projekten und Eindrücken erzählen: